
Implementation of MetaGAN: An Adversarial Approach to Few-Shot Learning
Published:
Background
Humans can recognize objects from a few examples. Having seen a lot of animal images before, given very few images of novel animals, we can recognize them easily. But for deep learning models, we have to train them from scratch to learn a new task. Transfer Learning and fine-tuning are some of the techniques to adapt trained models to learn a new task. The problem with them is that such models are trained only on a single task; adapting to a completely new task needs manual verification of similarity between these tasks. One of the recent approaches to this is the concept of meta-learning. The purpose of meta-learning schemes is to share information between the models being trained on similar tasks by using adaptation strategies to extract patterns that are useful for more than one task.
Learning from a small number of samples presents another difficulty for machine learning. The few-shot learning and zero-shot learning frameworks teach models to generalize to new datasets using relatively few samples. A K-shot classification problem, for instance, requires the model to generalize using just K examples: in the extreme case, the model generalizes using zero examples in zero-shot learning.
The model must adapt to new tasks with few instances and training iterations when the context of few-shot learning is added in meta-learning schemes. For example, with the model trained on various languages’ handwritten digit recognition tasks, with only a few handwritten examples per alphabet in a completely new language and very few training iterations, the model needs to generalize to that new language. To do this, a series of tasks are used to train the model or learner (character recognition model) during the meta-learning phase (e.g., different language character recognition). Instead of forcing the model or learner to focus on a specific task, we allow them to acquire intrinsic features that are generally applicable to all tasks in the task distribution \(P(\mathrm{T})\). Our goal is to identify model parameters (meta-learning phase) that are responsive to task changes such that minor changes in the parameters (adaptation phase) result in significant gains in the loss function for each task taken from \(P(\mathrm{T})\).
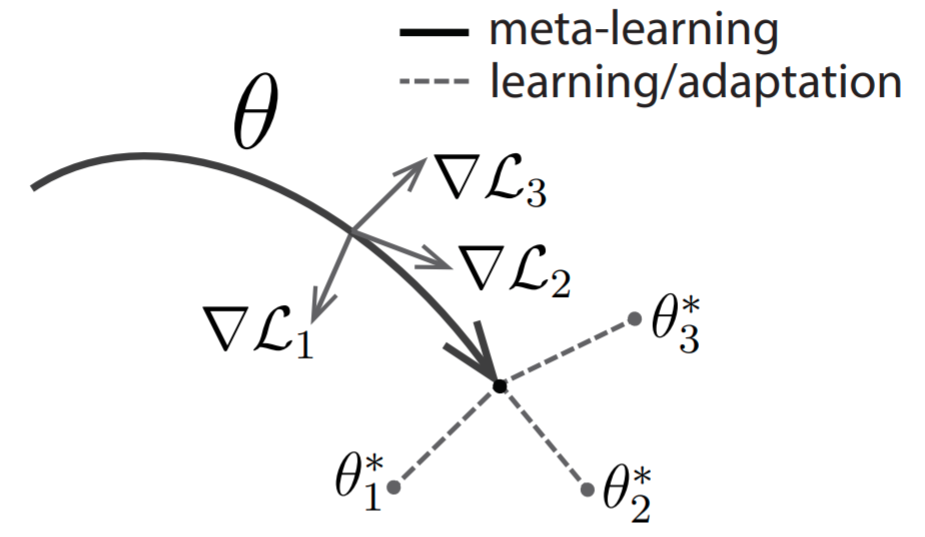 |
|---|
| Fig 1: Diagram showing meta-learning and adaptation phase. Source: MAML Paper |
MetaGAN is a simple and general framework for few-shot learning problems. Given a K-shot(number of samples per class in a training task) and an N-way(number of classes in a task) classifier, a conditional task generator generates samples that are not distinguishable from true data samples drawn from the task used to condition it. We now need to train the classifier(discriminator in GAN but with N output units for N-way classification) and generator in an adversarial setup.
What is the gain of using GAN in few-shot meta-learning? In a few-shot classification problem, the model tries to find a decision boundary for each task with just a few samples in each class. With very few samples, so many decision boundaries can be made, but most of them will not generalize well. Meta-learning tries to mitigate this problem by trying to learn a shared strategy across different tasks to form a decision boundary from a few samples in the hope that the strategy of making decision boundaries generalizes well to new tasks. Although this is plausible, there might be some problems. For example, some objects look more similar than others. It may be easier to form a decision boundary between a Chinese alphabet and an English alphabet than between a Chinese alphabet and a Korean alphabet. If the training data does not contain tasks that try to separate the Chinese alphabet from the Korean alphabet, the learner may find it difficult to extract the correct features to separate these two classes of objects. However, on the other hand, the expectation to have all kinds of class combinations during training leads to the combinatorial explosion problem. This is where MetaGAN helps. The generator in MetaGAN generates fake data. This forces the classifier(discriminator) to learn a sharper decision boundary. Instead of a classifier learning to separate Chinese and Korean alphabets, MetaGAN also forces it to learn to distinguish between real and fake Chinese and Korean alphabets, as shown in the figure below. Moreover, we don’t need the generator to generate data that are exactly similar to true data. It is better if the generator learns a bit off about data manifold.
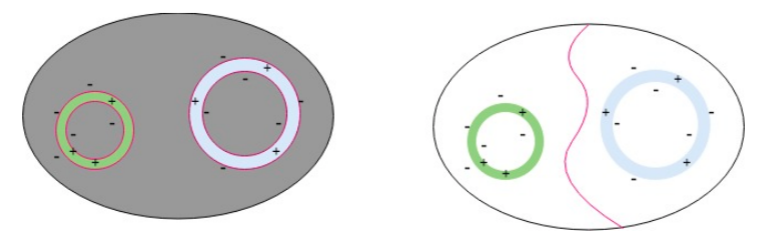 |
|---|
| Fig 2: Decision Boundary with MetaGAN(left) and Decision Boundary without MetaGAN(right). Colors represent different classes: gray means fake classes, and green and bluish can be real characters’ images from different languages. + and - means real and fake samples. Source: MetaGAN Paper |
Objective
The objective of this blog is to show you the implementation of MetaGAN. While some basics of GAN are expected from you before you delve deeper into this implementation, you will learn about meta-learning and semi-supervised classification. After reading this blog, you’ll realize that GANs can be used for purposes other than as generative models. For the reason that our only purpose is to generate samples that are plausible with real data, we ignore the discriminator when the vanilla GAN training is finished. When the discriminator is extended to output class labels, we can use it to perform supervised and semi-supervised classification, which helps in utilizing unlabeled data with very few labeled data to increase performance. Implementing meta-learning on top of that, you will see that with very few training iterations, our classifier will be able to achieve very significant performance.
Implementation
Basic Library Imports
Start with basic library imports and environment setup.
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
tf.__version__
'2.8.2'
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
print(e)
Dataset Preparation
Omniglot Dataset
We will use Omniglot Dataset which contains 1623 different handwritten characters from 50 different languages. Each character has 20 samples, so in total 32460 samples exist in the dataset. This dataset is particularly used for few-shot learning problems and is available in Tensorflow Dataset resources. Let’s import it.
import tensorflow_datasets as tfds
omniglot, info = tfds.load('omniglot', with_info=True)
info # see the info about omniglot dataset here
tfds.core.DatasetInfo(
name='omniglot',
full_name='omniglot/3.0.0',
description="""
Omniglot data set for one-shot learning. This dataset contains 1623 different
handwritten characters from 50 different alphabets.
""",
homepage='https://github.com/brendenlake/omniglot/',
data_path='~/tensorflow_datasets/omniglot/3.0.0',
file_format=tfrecord,
download_size=17.95 MiB,
dataset_size=12.29 MiB,
features=FeaturesDict({
'alphabet': ClassLabel(shape=(), dtype=tf.int64, num_classes=50),
'alphabet_char_id': tf.int64,
'image': Image(shape=(105, 105, 3), dtype=tf.uint8),
'label': ClassLabel(shape=(), dtype=tf.int64, num_classes=1623),
}),
supervised_keys=('image', 'label'),
disable_shuffling=False,
splits={
'small1': <SplitInfo num_examples=2720, num_shards=1>,
'small2': <SplitInfo num_examples=3120, num_shards=1>,
'test': <SplitInfo num_examples=13180, num_shards=1>,
'train': <SplitInfo num_examples=19280, num_shards=1>,
},
citation="""@article{lake2015human,
title={Human-level concept learning through probabilistic program induction},
author={Lake, Brenden M and Salakhutdinov, Ruslan and Tenenbaum, Joshua B},
journal={Science},
volume={350},
number={6266},
pages={1332--1338},
year={2015},
publisher={American Association for the Advancement of Science}
}""",
)
Being aware of following few shot learning problem statements(extracted from MetaGAN paper) that helps in dataset preparation for MetaGAN.
Given a distribution of tasks \(P(T)\), a sample task \(T\) from \(P(T)\) is given by a joint distribution \(P^T_{X \times Y}(x, y)\), where the task is to predict \(y\) given \(x\). We have a set of training sample tasks \(\{T_i\}^N_{i=1}\). Each training sample task \(T\) is a tuple \(T = (S_T, Q_T)\), where the support set is denoted as \(S_T = S^s_T \cup S^u_T\), and the query set is denoted as \(Q_T = Q^s_T \cup Q^u_T\). The supervised support set \(S^s_T = \{(x_1, y_1), (x_2, y_2), \cdots (x_{N×K}, y_{N×K})\}\) contains \(K\) labeled samples from each of the \(N\) classes (this is usually known as \(K\)-shot \(N\)-way classification). The optional unlabeled support set \(S^u_T = \{(x^u_1 , x^u_2 , \cdots x^u_M\}\) contains unlabeled samples from the same set of \(N\) classes, which can also be empty in purely supervised cases. \(Q^s_T = \{(x_1, y_1), (x_2, y_2), \cdots (x_T, y_T)\}\) is the supervised query dataset. \(Q^u_T = \{x_1, x_2, \cdots x_P\}\) is the optional unlabeled query dataset. The objective of the model is to minimize the loss of its predictions on a query set, given the support set as input.
Simply put, for each alphabet in the omniglot dataset, we will keep K-shot(K-support in code) samples in the support set and K-query samples in the query set. Since the omniglot dataset doesn’t have any unlabeled samples, we don’t need to prepare an unlabeled support set and a query set. Whenever we require an unlabeled set, we will replace it with the corresponding labeled support set and labeled query set. A task is prepared by selecting N classes, each having K-shot support samples and K-query query samples. The support set will be used to fine tune the learner(adaptation), and the query set will be used to evaluate the adapted learner. Accumulated evaluation loss from a query set of a number of tasks will be used to update the learner to the best position from where, with very few gradient updates, the learner can be adapted to a new task.
We will be doing \(5\)-way, \(5\)-shot, \(15\)-query meta learning with 32 tasks for single meta update. Omniglot dataset contains images with size \(105 \times 105\) and \(3\) channels. We will resize it to \(28 \times 28\). All channels in images in Omniglot are same, so we can achieve our objective with single channel only. We will create a task by randomly selecting \(5\) labels from the train set, regardless of their alphabets. That means a single task can contain alphabets from different languages.
n_way = 5
k_support = 5 # alias of K in K-shot
k_query = 15
task_batch = 32 # number of task for single meta update
image_size = [28, 28]
num_of_channels = 1
noise_dim = 100 # number of dimension in latent space from where noise is sampled
Dataset preparation steps
- Just take image and their corresponding labels. Ignore all others info in Omniglot Samples
- Group train and test omniglot dataset samples by its label in a batch of
(k_support + k_query)samples. Filter out group with samples less than(k_support + k_query). Before that shuffle dataset so that samples filtered out in one iteration gets chance to be involved in next iteration. - Resize and normalize between [-1, 1]
- Randomly rotate all images in a class by one of 0, 90, 180, 270 degree to create new class image.
- Take random
n_waylabels and batch them to form a single task. Ignore task with number of classes less thann_way. - Relabel images in a task. Relabel them to class [0, 1, …, n_way-1] for
n_waydifferent classes in a task - Split
n_waytask into support set and query set. - For training dataset take
task_batchtasks and batch into one. One task batch will be used for one metalearning step.
def get_images_and_labels(sample):
"""Returns image and corresponding labels from omniglot samples.
A Omniglot samples is a dictionary with following structure.
`{alphabet: (), alphabet_char_id: (), image: (105, 105, 3), label: ()}`
Parameters
----------
sample : `dict` of Omniglot sample
Returns
----------
image : `Tensor` of dtype `tf.float32`
Image tensor shaped [105, 105, 3] in `sample` dictionary
label : `Tensor` of dtype `tf.int64`
Scalar Label tensor in `sample` dictionary
"""
image = tf.cast(sample['image'], tf.float32)
label = tf.cast(sample['label'], tf.int64)
return image, label
def get_label_group_func(dataset):
"""Returns a dataset where grouping of omniglot sample by its label
and reduction of them to batch of size `k_support + k_query` is done
Returns
----------
dataset :
A `tf.data.Dataset` transformation function, which can be passed to `tf.data.Dataset.apply`
"""
dataset = dataset.group_by_window(key_func=lambda x, y: y,
reduce_func=lambda _, els: els.batch(k_support + k_query),
window_size=k_support + k_query)
return dataset
def label_group_filter(images, labels):
"""A predicate to check if labeled group Omniglot images
has exactly `k_support + k_query` samples. Otherwise we
cannot make support set and query set from this label group.
Ignore them.
Parameters
----------
images : `Tensor` of dtype `tf.float32`
Shape `[k_support + k_query, h, w, c]`
Images from Omniglot with same labels
labels : `Tensor` of dtype `tf.int64`
Shape `[k_support + k_query,]`
Corresponding labels of input images. They must be same here
Returns
----------
right_size_label_group : `boolean`
`True` if images have `k_support + k_query` samples else `False`
"""
right_size_label_group = tf.shape(images)[0] == (k_support + k_query)
return right_size_label_group
def resize_and_normalize(images, labels):
"""Resize image and normalize them in between `[-1, 1]`.
Parameters
----------
images : `Tensor` of dtype `tf.float32`
Shape `[k_support + k_query, height, width, channels]`
labels : `Tensor` of dtype `tf.int64`
Shape `[k_support + k_query, height, width, channels,]`
Corresponding labels of input `images`.
Returns
----------
images : `Tensor` of dtype `tf.float32`
Shape ``
Resized and normalized `images` with shape `image_size` and values in between `[-1, 1]`
Returns images with only first `num_of_channels` channels.
All channels in Omniglot dataset are same.
labels : `Tensor` of dtype `tf.int64`
Same as input labels.
"""
images = tf.image.resize((images[:, :, :, :num_of_channels]-127.5)/127.5, image_size)
return images, labels
def data_augment(images, labels):
"""Data augmentation by randomly rotating each image by a
multiple of 90 degrees to form new classes.
Parameters
----------
images : `Tensor` of dtype `tf.float32`
Shape `[k_support + k_query, height, width, channels]`
`k_support + k_query` samples in `images` should be from same class.
labels : `Tensor` of dtype `tf.int64`
Shape `[k_support + k_query,]`
Corresponding labels of input `images`. Here all labels should be same.
Returns
----------
images: `Tensor` of dtype `tf.float32`
Shape same as input `images`
labels : `Tensor` of dtype `tf.int64`
Same as input labels. We can consider same label for new class
as in old class since all images are rotated by same angle.
"""
rotation = tf.random.uniform([], maxval=4, dtype=tf.int32)
images = tf.image.rot90(images, k=rotation)
return images, labels
def relabel(images, labels):
"""Relabel images for `n_way` classification.
Parameters
----------
images : `Tensor` of dtype `tf.float32`
Shape `[n_way, k_query + k_support, height, width, channels]`
Images for a single task managed in 5D tensor.
--> 1st dimension: for `n_way` classes
--> 2nd dimension: for `k_query + k_support` images samples for a class
--> Other dimensions: Images height, width and channels
labels : `Tensor` of dtype `tf.int64`
Shape `[n_way, k_query + k_support]`
Omniglot labels for images in same structure as input `images`.
Labels value for images from each class can be any value betwenn 0 to 1622(total alphabets-1)
Returns
----------
images : `Tensor` of dtype `tf.float32`
Returns same input `images`. No changes required here.
new_labels : `Tensor` of dtype `tf.int64`
Shape `[n_way, k_query + k_support]`
New labels value must be between `[0, n_way-1]`
"""
old_labels_shape = tf.shape(labels)
new_classes = tf.expand_dims(tf.range(old_labels_shape[0]), -1)
new_labels = tf.tile(new_classes, [1, old_labels_shape[-1]])
new_labels = tf.cast(new_labels, tf.int64)
return images, new_labels
def get_support_query_split_func(shuffle=True):
"""Returns a function that will split a task into support set and query set
Parameters
----------
shuffle : `boolean`
Flags whether to shuffle before splitting `n_way` task into support set and query set.
If not take first `k_support` into support set and remaining into query set.
Returns
----------
support_query_split : `function`
A function that will split a task into support set and query set.
"""
def support_query_split(nway_images, nway_labels):
"""Split `n_way` task into `k_support`s support set and `k_query` query set.
Parameters
----------
nway_images : `Tensor` of dtype `tf.float32`
Shape `[n_way, k_query + k_support, height, width, channels]`
`k_query + k_support` images for each class in `n_way` task.
nway_labels : `Tensor` of dtype `tf.int64`
Shape `[n_way, k_query + k_support]`
N-way labels for images in same structure as input `nway_images`.
Returns
----------
support_images : `Tensor` of dtype `tf.float32`
Shape `[n_way, k_support, height, width, channels]`
Used for adaptation(K-shot learning).
support_labels : `Tensor` of dtype `tf.int64`
Shape `[n_way, k_support]`
Used for adaptation(K-shot learning).
query_images : `Tensor` of dtype `tf.float32`
Shape `[n_way, k_query, height, width, channels]`
Used for metalearning step(Testing adapted learner).
query_labels : `Tensor` of dtype `tf.int64`
Shape `[n_way, k_query]`
Used for metalearning step(Testing adapted learner).
"""
images_shape = tf.shape(nway_images)
perm = tf.random.shuffle(tf.range(images_shape[1])) if shuffle \
else tf.range(images_shape[1])
support_images = tf.gather(nway_images, perm[:k_support], axis=1)
support_images = tf.reshape(support_images, (-1, images_shape[-3], images_shape[-2], images_shape[-1]))
support_labels = tf.gather(nway_labels, perm[:k_support], axis=1)
support_labels = tf.reshape(support_labels, [-1])
query_images = tf.gather(nway_images, perm[k_support:], axis=1)
query_images = tf.reshape(query_images, (-1, images_shape[-3], images_shape[-2], images_shape[-1]))
query_labels = tf.gather(nway_labels, perm[k_support:], axis=1)
query_labels = tf.reshape(query_labels, [-1])
return support_images, support_labels, query_images, query_labels
return support_query_split
As mentioned in dataset preparation steps, we use above defined function in tf.data.Dataset pipeline. You can see in Omniglot info above, The dataset has TRAIN, TEST and other splits(not used). Remember, we do no shuffling in test dataset.
train_dataset_task_grouped = omniglot['train']\
.map(get_images_and_labels)\
.shuffle(19280, reshuffle_each_iteration=True)\
.group_by_window(key_func=lambda x, y: y, # Group by label
reduce_func=lambda _, els: els.batch(k_support + k_query), # Batch size is k_support + k_query
window_size=k_support + k_query)\
.filter(label_group_filter)\
.map(resize_and_normalize)\
.map(data_augment)\
.shuffle(964, reshuffle_each_iteration=True)\
.batch(batch_size=n_way, drop_remainder=True)\
.map(relabel)\
.map(get_support_query_split_func(shuffle=True))\
.batch(batch_size=task_batch)
test_dataset_nway_grouped = omniglot['test']\
.map(get_images_and_labels)\
.group_by_window(key_func=lambda x, y: y, # Group by label
reduce_func=lambda _, els: els.batch(k_support + k_query), # Batch size is k_support + k_query
window_size=k_support + k_query)\
.filter(label_group_filter)\
.map(resize_and_normalize)\
.batch(batch_size=n_way, drop_remainder=True)\
.map(relabel)\
.map(get_support_query_split_func(shuffle=False))
Now define a utility function to generate noise from normal distribution.
def generate_noise(shape):
"""Generate noise from normal distribution.
Parameters
----------
shape: `tuple` of `int` or `tf.int` or both.
Shape of noise tensor to generate.
Returns
----------
noise: `Tensor` of dtype `tf.float32`
Noise tensor shaped `shape` from normal distribution.
"""
noise = tf.random.normal(shape)
return noise
Model Creation
Generator
The generator should be able to generate fake data that is close to real data manifold in specific task \(T\). That means we need to condition generator on task basis. For that, we compress the information in the task’s support dataset with a dataset encoder \(E\) into vector \(h_T\), which contains sufficient statistics for the data distribution of task \(T\). The task representation vector \(h_T\) is than concatenated with noise input \(z\) to be input to the generator network. The task encoder contains two modules. The Instance-Encoder encodes each samples and feature aggregation module produce representation vector \(h_T\) for the whole training task set by some aggrefation scheme like averaging, max-pooling, etc.
Implementation of Task Encoder Model.
class TaskEncoder(tf.keras.Model):
"""Takes a task $$T$$ support set and generates a representation vector $$h_T$$.
Parameters
----------
conv_filters : `list` of `int`
List of number of filters to use in each `Conv2D` layers.
The length of list is the number of `Conv2D` layers to use.
conv_kernels : `list` of `int` or `tuples` or both.
List of kernel size to use in each corresponding `Conv2D` layers.
conv_strides : `list` of `int` or `tuples` or both.
List of strides to use in each corresponding `Conv2D` layers.
output_units : `int`
Dimension of Task representation.
Input shape
----------
N-D tensor with shape: `(n_way*k_support, height, width, channels)`
Whole support set for a task must be given to this model
Output shape
----------
N-D tensor with shape: `(1, output_units)`
Single representation vector for the whole task set.
"""
def __init__(self,
conv_filters,
conv_kernels,
conv_strides,
output_units,
**kwargs):
super(TaskEncoder, self).__init__(**kwargs)
self.conv2d_layers = [tf.keras.layers.Conv2D(filters=f,
kernel_size=k,
strides=s,
padding='same')
for f, k, s in zip(conv_filters,
conv_kernels,
conv_strides)]
self.activation_layers = [tf.keras.layers.LeakyReLU()
for _ in conv_filters]
self.flatten_layer = tf.keras.layers.Flatten()
self.output_layer = tf.keras.layers.Dense(output_units)
self.output_activation = tf.keras.layers.LeakyReLU()
self.output_dropout = tf.keras.layers.Dropout(rate=0.2)
def call(self, inputs):
for conv, activation in zip(self.conv2d_layers,
self.activation_layers):
inputs = conv(inputs)
inputs = activation(inputs)
outputs = self.flatten_layer(inputs)
outputs = self.output_layer(outputs)
outputs = self.output_activation(outputs)
outputs = self.output_dropout(outputs)
task_repr = tf.reduce_mean(outputs, axis=0, keepdims=True)
return task_repr
conv_filters=[64, 64, 128, 128, 256, 256]
conv_kernels=[3, 3, 3, 3, 3, 3]
conv_strides=[1, 2, 1, 2, 1, 2]
output_units=256
task_encoder = TaskEncoder(conv_filters=conv_filters,
conv_kernels=conv_kernels,
conv_strides=conv_strides,
output_units=output_units)
Implementation of Task Conditioned Generative Model
Note: No batchnormalization is used here.
class ConditionalGenerator(tf.keras.Model):
"""Task conditioned generator
Parameters
----------
conv_start_shape : `tuple` of length 3
The conditioned noise will be projected to `np.prod(conv_start_shape)`
and reshaped to `conv_start_shape`. To this output we can perform
convolutional operation.
upsample_scales : `list` of `int`
Instead of `Conv2DTranspose`, we use `Upsample + Conv2D`. It is the
list of scale sizes for upsampling before corresponding convolutional layers.
conv_filters : `list` of `int`
List of number of filters to use in each `Conv2D` layers.
The length of list is the number of `Conv2D` layers to use.
conv_kernels : `list` of `int` or `tuples` or both.
List of kernel size to use in each `Conv2D` layers.
Input shape
----------
Tuple of N-D tensor of length 2 and with shapes:
`[(n_way*k_support, noise_dim), (1, task_repr_size)]` during adaptation
or `[(n_way*k_query, noise_dim), (1, task_repr_size)]` during metalearning
1st element in tuple is noise and 2nd is task representation vector to condition generator.
Output shape
----------
N-D tensor with shape:
`(n_way*k_support, height, width, channels)` during adaptation
`(n_way*k_query, height, width, channels)` during metalearning
"""
def __init__(self,
conv_start_shape,
upsample_scales,
conv_filters,
conv_kernels,
**kwargs):
super(ConditionalGenerator, self).__init__(**kwargs)
self.concatenation = tf.keras.layers.Concatenate()
self.noise_embedding_projection = tf.keras.layers.Dense(np.prod(conv_start_shape))
self.noise_embedding_reshape = tf.keras.layers.Reshape(conv_start_shape)
self.upsample_layers = [tf.keras.layers.UpSampling2D(size=scale)
for scale in upsample_scales]
self.conv_layers = [tf.keras.layers.Conv2D(filters=f,
kernel_size=k,
padding='same')
for f, k in zip(conv_filters,
conv_kernels)]
self.activation_layers = [tf.keras.layers.LeakyReLU()
for _ in range(len(conv_filters) - 1)]\
+ [tf.keras.layers.Activation('tanh'),]
def call(self, inputs):
noise, task_representation = inputs
task_encodings = tf.tile(task_representation, [tf.shape(noise)[0], 1])
contitioned_noise = self.concatenation([noise, task_encodings]) # noise is now task conditioned
# Now, Same as normal gan except upsample instead of convtranspose.
output_image = self.noise_embedding_reshape(self.noise_embedding_projection(contitioned_noise))
for upsample, conv, activation in zip(self.upsample_layers,
self.conv_layers,
self.activation_layers):
output_image = upsample(output_image)
output_image = conv(output_image)
output_image = activation(output_image)
return output_image
generator = ConditionalGenerator(conv_start_shape=(7, 7, 256),
upsample_scales=[1, 2, 2],
conv_filters=[128, 64, num_of_channels],
conv_kernels=[5, 5, 5])
Discriminator
MetaGAN discriminator can be any few shot classifiers. We will be using one from Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks Chelsea
Implementation of Discriminator/Classifier Model
class Discriminator(tf.keras.Model):
"""The Discriminator/Classifier network for MetaGAN.
Parameters
----------
conv_filters : `list` of `int`
List of number of filters to use in each `Conv2D` layers.
The length of list is the number of `Conv2D` layers to use.
conv_kernels : `list` of `int` or `tuples` or both.
List of kernel size to use in each `Conv2D` layers.
conv_strides : `list` of `int` or `tuples` or both.
List of strides to use in each `Conv2D` layers.
Input shape
----------
N-D tensor with shape: `(batch_size, height, width, channels)`.
Output shape:
----------
Tuple of 2 N-D tensor with shape: `[(batch_size, n_way), (batch_size, flattened_size)]`.
Tuple of length 2 with 1st element classifier logit output and
2nd element flattened last convolutional layer output.
"""
def __init__(self,
conv_filters,
conv_kernels,
conv_strides,
n_way,
**kwargs):
super(Discriminator, self).__init__(**kwargs)
self.conv2d_layers = [tf.keras.layers.Conv2D(filters=f,
kernel_size=k,
strides=s,
padding='same')
for f, k, s in zip(conv_filters,
conv_kernels,
conv_strides)]
self.batchnorm_layers = [tf.keras.layers.BatchNormalization()
for _ in conv_filters]
self.activation_layers = [tf.keras.layers.ReLU()
for _ in conv_filters]
self.flatten_layer = tf.keras.layers.Flatten()
self.output_layer = tf.keras.layers.Dense(n_way)
def call(self, inputs):
for conv, batchnorm, activation in zip(self.conv2d_layers,
self.batchnorm_layers,
self.activation_layers):
inputs = conv(inputs)
inputs = batchnorm(inputs, training=True)
inputs = activation(inputs)
flattened_features = self.flatten_layer(inputs)
class_logits = self.output_layer(flattened_features)
return class_logits, flattened_features
discriminator = Discriminator(conv_filters=[64, 64, 64, 64],
conv_kernels=[3, 3, 3, 3],
conv_strides=[2, 2, 2, 2],
n_way=n_way)
# We require two discriminators to restore previous weights after trial of meta learning step
duplicate_discriminator = Discriminator(conv_filters=[64, 64, 64, 64],
conv_kernels=[3, 3, 3, 3],
conv_strides=[2, 2, 2, 2],
n_way=n_way)
Optimizers and Loss Functions
We’ll use hyperparameters that are choosen according to MetaGAN paper and Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks Chelsea
meta_learning_rate=1e-3
meta_beta_1 = 0.5
meta_beta_2 = 0.9
adaption_learning_rate=0.1
adaptation_number_of_steps = 5
EPOCHS = 100
For adaptation steps, use SGD, and for meta learning, use adam optimizer with above defined parameters.
adaptation_optimizer = tf.keras.optimizers.SGD(learning_rate=adaption_learning_rate) # used for inner gradient update
meta_discriminator_optimizer = tf.keras.optimizers.Adam(learning_rate=meta_learning_rate,
beta_1=meta_beta_1,
beta_2=meta_beta_2)
meta_generator_optimizer = tf.keras.optimizers.Adam(learning_rate=meta_learning_rate,
beta_1=meta_beta_1,
beta_2=meta_beta_2)
As mentioned in the paper, discriminator loss can be divided into two parts. One that represents the GAN problem, the unsupervised loss and the other that represents the individual n_way class probabilities, the supervised loss. To get the classification probabilities, we feed the logits through the softmax function. However, We still need a way to represent the probability of an input image being real rather than fake. That is, we still need to account for the binary classification problem of regular a GAN. We know that the logits are in terms of softmax probability values. Yet, we need a way to represent them as sigmoid logits as well. We know that the probability of an input being real corresponds to the sum over all real class logits. With that mind, we can feed these values to a LogSumExp function that will model the binary classification value. After that, we feed the result from the LogSumExp to a sigmoid function as binary classification logits. Using the Tensorflow’s LogSumExp built-in function helps to avoid numerical problems. This routine prevents over/under flow issues that may occur when LogSumExp encounters very extreme, either positive or negative values.
As usual in vanilla GAN, for images coming from the training set, we maximize their probabilities of being real by assigning labels of 1s. For fabricated images coming from the generator, we maximize their probabilities to be fake by giving them labels of 0s.
Implementation Labeled/Supervised Cross Entropy Loss
def labeled_loss(target, class_logits):
"""Loss function to calculate supervised loss.
Parameters
----------
target : `Tensor` of dtype `tf.int64`
Shape `(batch_size,)`
Categorical labels for `n_way` classification
class_logits : `Tensor` of dtype `tf.float32`
Shape `(batch_size, n_way)`
It's a logit tensor.
Returns
----------
loss : Scalar `Tensor` of dtype `tf.float32`
Supervised cross entropy loss for labeled input
"""
losses = tf.keras.losses.sparse_categorical_crossentropy(target, class_logits, from_logits=True)
loss = tf.reduce_mean(losses)
return loss
Implementation of Unlabeled/Unsupervised Loss
For both real and generated images
def unlabeled_loss(class_logits, real=True):
"""Loss function to calculate supervised loss.
Parameters
----------
class_logits : `Tensor` of dtype `tf.float32`
Shape `(batch_size, n_way)`
It's a class logit tensor predicted by model for unlabeled input.
real : `boolean`
Flags whether `class_logits` is for real unlabeled data or for unlabeled generated data.
Returns
----------
loss : Scalar `Tensor` of dtype `tf.float32`
Unsupervised loss for unlabeled input.
"""
gan_logits = tf.reduce_logsumexp(class_logits, axis=1)
labels = tf.ones_like(gan_logits) if real else tf.zeros_like(gan_logits)
losses = tf.keras.losses.binary_crossentropy(labels, gan_logits, from_logits=True)
loss = tf.reduce_mean(losses)
return loss
Implementation of Discriminator Loss
def discriminator_loss(label_class_logits,
label_target,
unlabel_class_logits,
fake_class_logits):
"""Function that estimates how well the discriminator is able to distinguish real images from fakes.
discriminator_loss = supervised loss + real unsupervised loss + fake unsupervised loss.
Parameters
----------
label_class_logits : `Tensor` of dtype `tf.float32`
Shape `(batch_size, n_way)`
Classfier predicted class logits for labeled real data.
label_target : `Tensor` of dtype `tf.int32`
Shape `(batch_size,)`
True categorical labels of `label_class_logits` for `n_way` classification.
unlabel_class_logits : `Tensor` of dtype `tf.float32`
Shape `(batch_size, n_way)`
Classfier predicted class logits for unlabeled real data.
fake_class_logits : `Tensor` of dtype `tf.float32`
Shape `(batch_size, n_way)`
Classfier predicted class logits for unlabeled generated data.
Returns
----------
loss : Scalar `Tensor` of dtype `tf.float32`
"""
supervised_loss = labeled_loss(label_target, label_class_logits)
real_unsupervised_loss = unlabeled_loss(unlabel_class_logits, real=True)
fake_unsupervised_loss = unlabeled_loss(fake_class_logits, real=False)
disc_loss = supervised_loss + real_unsupervised_loss + fake_unsupervised_loss
return disc_loss
Implementation of Generator Loss
As described in the Improved Techniques for Training GANs paper, we use feature matching for the generator loss. Have a look at the author’s quote about feature matching: “Feature matching is the concept of penalizing the mean absolute error between the average value of some set of features on the training data and the average values of that set of features on the generated samples.” So, we take the average of the features of samples extracted from the discriminator when a real training minibatch is being processed and in same way take average of features for generated data samples. The generator loss is the mean squared difference between them.
def generator_loss(real_features, fake_features):
"""The generator's loss quantifies how well it was able to trick the discriminator.
Parameters
----------
real_features : `Tensor` of dtype `tf.float32`
Shape : `(batch_size, flattened_size)`
Flattened last convolutional layer output for real input data batch
real_features : `Tensor` of dtype `tf.float32`
Shape : `(batch_size, flattened_size)`
Flattened last convolutional layer output for generated input data batch
Returns
----------
loss : Scalar `Tensor` of dtype `tf.float32`
"""
real_mean_feature = tf.reduce_mean(real_features, axis=0)
fake_mean_feature = tf.reduce_mean(fake_features, axis=0)
gen_loss = tf.reduce_mean((real_mean_feature - fake_mean_feature)**2)
return gen_loss
Implementation of Accuracy, an evaluation metric
def accuracy(class_logits, labels):
"""Accuracy measure for given class logits and target labels.
Parameters
----------
class_logits : `Tensor` of dtype `tf.float32`
Shape `(batch_size, n_way)`
It's a logit tensor.
labels : `Tensor` of dtype `tf.int64`
Shape `(batch_size,)`
True categorical labels of `class_logits` for `n_way` classification.
Returns
----------
accuracy : `Tensor` of dtype `tf.float32`
Accuracy measure for given class logits and target labels.
"""
label_predictions = tf.argmax(class_logits, axis=-1)
equality = tf.equal(labels, label_predictions)
return tf.reduce_mean(tf.cast(equality, tf.float32))
Training
Define an adaptaion function.
def adaptation(learner, real_support, real_support_label, fake_support):
"""Given a learner model, perform `adaptation_number_of_steps`
gradient descent using supervised support set, generated fake support set
and same supervised support set as unsupervised support set as we don't
have unlabeled omniglot images.
Parameters
----------
learner : `tensorflow.keras.Model`
A few shot classifier model which needs to be adapted to given task support set.
real_support : `Tensor` of dtype `tf.float32`
Shape `(n_way*k_support, height, width, channels)`
Target task support images
real_support_label : `Tensor` of dtype `tf.int64`
Shape `(n_way*k_support,)`
`n_way` labels of given real support set
fake_support : `Tensor` of dtype `tf.float32`
Shape `(n_way*k_support, height, width, channels)`
Generated images conditioned on same task as input real support images task.
Returns
----------
support_loss : Scalar Tensor of dtype `tf.float32`
Support loss during last step of adaptation of given `learner`.
"""
support_disc_losses = []
for _ in range(adaptation_number_of_steps):
with tf.GradientTape() as adaptation_tape:
support_real_class_logits, _ = learner(real_support)
support_fake_class_logits, _ = learner(fake_support)
disc_loss = discriminator_loss(support_real_class_logits,
real_support_label,
support_real_class_logits,
support_fake_class_logits)
adaptation_grads = adaptation_tape.gradient(disc_loss, learner.trainable_variables)
adaptation_optimizer.apply_gradients(zip(adaptation_grads, learner.trainable_variables))
support_disc_losses.append(disc_loss)
return tf.reduce_mean(support_disc_losses)
@tf.function
def meta_learn_step(support_taskbatch,
support_taskbatch_labels,
query_taskbatch,
query_taskbatch_labels):
"""Perform one step of metalearning given a batch of tasks.
Parameters
----------
support_taskbatch : `Tensor` of dtype `tf.float32`
Shape `(task_batch, n_way*k_support, height, width, channels)`
Support set images for task batch.
support_taskbatch_labels : `Tensor` of dtype `tf.int64`
Shape `(task_batch, n_way*k_support,)`
Support set images for task batch set labels for the task batch.
query_taskbatch : `Tensor` of dtype `tf.float32`
Shape `(task_batch, n_way*k_query, height, width, channels)`
Query set images for task batch.
query_taskbatch_labels : `Tensor` of dtype `tf.int64`
Shape `(task_batch, n_way*k_query,)`
Query set images for task batch set labels for the task batch.
Returns
----------
taskbatch_query_discriminator_loss : Scalar Tensor of dtype `tf.float32`
Average discriminator loss over task batch on query set
task_batch_query_generator_loss : Scalar Tensor of dtype `tf.float32`
Average generator loss over task batch on query set
taskbatch_query_accuracy : Scalar Tensor of dtype `tf.float32`
Average accuracy over task batch on query set
"""
number_of_tasks = support_taskbatch.shape[0]
# Step 1. Store discriminator weights in another model,
# Both model should be built before executing this step
for dup_wts, wts in zip(duplicate_discriminator.trainable_variables,
discriminator.trainable_variables):
dup_wts.assign(wts)
# Step 2. Initialize tensor to find total losses and accuracies on various tasks
taskbatch_query_discriminator_loss = tf.constant(0.0)
task_batch_query_generator_loss = tf.constant(0.0)
taskbatch_query_accuracy = tf.constant(0.0)
with tf.GradientTape() as meta_discriminator_tape, tf.GradientTape() as meta_generator_tape:
## Step 3. Repeat Step 4-12 for all tasks in current task batch.
for task_no in range(number_of_tasks):
# Step 4. For each task, find its representation vector using support set and TaskEncoder model.
task_representation = task_encoder(support_taskbatch[task_no])
# Step 5. Adapt discriminator model to the current task, call `adaptation` function passing discriminator
# and required support inputs
with meta_discriminator_tape.stop_recording(), meta_generator_tape.stop_recording():
# No need to recording operatin of adaptation for meta updates
# Generate fake support set with same number of samples as in real support set in current task
support_noise = generate_noise((tf.shape(support_taskbatch[task_no])[0], noise_dim))
support_fake = generator([support_noise, task_representation])
support_loss = adaptation(discriminator,
support_taskbatch[task_no],
support_taskbatch_labels[task_no],
support_fake)
# Step 6. Generate fake query set
query_noise = generate_noise((tf.shape(query_taskbatch[task_no])[0], noise_dim))
query_fake = generator([query_noise, task_representation])
# Step 7. Find discriminator feature and class logits for real and generated query set of current task
query_real_class_logits, query_real_features = discriminator(query_taskbatch[task_no])
query_fake_class_logits, query_fake_features = discriminator(query_fake)
# Step 8. Find discriminator loss
disc_loss = discriminator_loss(query_real_class_logits,
query_taskbatch_labels[task_no],
query_real_class_logits,
query_fake_class_logits)
# Step 9. Find generator loss
gen_loss = generator_loss(query_real_features, query_fake_features)
# Step 10. Add query discriminator loss and generator loss to recording variable.
taskbatch_query_discriminator_loss += disc_loss
task_batch_query_generator_loss += gen_loss
# Step 11. Calculate query accuracy for current task and add to the sum variable
query_accuracy = accuracy(query_real_class_logits, query_taskbatch_labels[task_no])
taskbatch_query_accuracy += query_accuracy
# Step 12. Recover discriminator weights before adaptation for next task adaptation.
for dup_wts, wts in zip(duplicate_discriminator.trainable_variables,
discriminator.trainable_variables):
wts.assign(dup_wts)
# Step 13. Find discriminator and generator gradients; TaskEncoder is updated along with Generator,
# So from total generator loss, find gradients wrt to both generator variables and task encoder variables
meta_discriminator_grads = meta_discriminator_tape.gradient(taskbatch_query_discriminator_loss,
discriminator.trainable_variables)
meta_generator_grads = meta_generator_tape.gradient(task_batch_query_generator_loss,
task_encoder.trainable_variables + generator.trainable_variables)
# Step 14. Using respective meta optimizer updates discriminator, generator and task encoder weights
meta_discriminator_optimizer.apply_gradients(zip(meta_discriminator_grads,
discriminator.trainable_variables))
meta_generator_optimizer.apply_gradients(zip(meta_generator_grads,
task_encoder.trainable_variables + generator.trainable_variables))
# Find average metrices for task batch to return
avg_disc_loss = taskbatch_query_discriminator_loss/number_of_tasks
avg_gen_loss = task_batch_query_generator_loss/number_of_tasks
avg_accuracy = taskbatch_query_accuracy/number_of_tasks
return avg_disc_loss, avg_gen_loss, avg_accuracy
# for a single task
@tf.function
def evaluation(support_images, support_labels, query_images, query_labels):
"""Perform finetuning/adaptation using support set of a task and
returns evaluation metrices calculated using query set of the same task.
Parameters
----------
support_images : `Tensor` of dtype `tf.float32`
Shape `(n_way*k_support, height, width, channels)`
support_labels : `Tensor` of dtype `tf.int64`
Shape `(n_way*k_support,)
query_images : `Tensor` of dtype `tf.float32`
Shape `(n_way*k_query, height, width, channels)`
query_labels : `Tensor` of dtype `tf.int64`
Shape `(n_way*k_query,)
Returns
----------
query_discriminator_loss : Scalar Tensor of dtype `tf.float32`
Classifier loss on query set of given task after adaptation on same task support set.
query_accuracy : `Tensor` of dtype `tf.float32`
Classifier accuracy on query set of given task after adaptation on same task support set.
"""
# During evaluation since no metalearning step is done, we will use secondary discriminator for adaptation
# and evaluation metrices calculation on query set.
# Step 1. Copy primary discriminator weights to secondary discriminator.
for dup_wts, wts in zip(duplicate_discriminator.trainable_variables, discriminator.trainable_variables):
dup_wts.assign(wts)
# Step 2. Produce fake support set and adapt secondary discriminator to passed task.
task_representation = task_encoder(support_images)
support_noise = generate_noise((tf.shape(support_images)[0], noise_dim))
support_fake = generator([support_noise, task_representation])
support_loss = adaptation(duplicate_discriminator,
support_images,
support_labels,
support_fake)
# Step 3. Produce fake query set with same number of samples as in real query set
query_noise = generate_noise((tf.shape(query_images)[0], noise_dim))
query_fake = generator([query_noise, task_representation])
# Step 4. Find class logits for real and fake query set. Since generator loss is irrelevant here
# Discriminator loss is ignored here.
query_real_class_logits, _ = duplicate_discriminator(query_images)
query_fake_class_logits, _ = duplicate_discriminator(query_fake)
# Step 5. Find discriminator loss
query_discriminator_loss = discriminator_loss(query_real_class_logits,
query_labels,
query_real_class_logits,
query_fake_class_logits)
# Step 6. Find accuracy on query set
query_accuracy = accuracy(query_real_class_logits, query_labels)
return query_discriminator_loss, query_accuracy
Training Loop
import os
checkpoint_dir = './training_checkpoints'
if not os.path.exists(checkpoint_dir):
os.mkdir(checkpoint_dir)
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(adaptation_optimizer=adaptation_optimizer,
meta_discriminator_optimizer=meta_discriminator_optimizer,
meta_generator_optimizer=meta_generator_optimizer,
task_encoder=task_encoder,
generator=generator,
discriminator=discriminator)
# To share same weights between primary discriminator and secondary discriminator
# manually intialize weights by calling build function
discriminator.build((None, image_size[0], image_size[1], num_of_channels))
duplicate_discriminator.build((None, image_size[0], image_size[1], num_of_channels))
gen_losses = []
disc_losses = []
accuracies = []
test_losses = []
test_accuracies = []
for ep in range(EPOCHS):
gen_loss = []
disc_loss = []
disc_accuracy = []
########################################### Training ################################################
for task_batch_no, (support_images, support_labels, query_images, query_labels) in enumerate(train_dataset_task_grouped):
d_loss, g_loss, acc = meta_learn_step(support_images,
support_labels,
query_images,
query_labels)
disc_loss.append(d_loss)
gen_loss.append(g_loss)
disc_accuracy.append(acc)
disc_loss = tf.reduce_mean(disc_loss)
gen_loss = tf.reduce_mean(gen_loss)
disc_accuracy = tf.reduce_mean(disc_accuracy)
disc_losses.append(disc_loss)
gen_losses.append(gen_loss)
accuracies.append(accuracy)
#####################################################################################################
#################################### Evaluation and Logging ################################################
if ep%10 == 0: # Every 10 epochs
test_loss = []
test_accuracy = []
for task_no, (support_images, support_labels, query_images, query_labels) in enumerate(test_dataset_nway_grouped):
query_loss, query_accuracy = evaluation(support_images, support_labels, query_images, query_labels)
test_loss.append(query_loss)
test_accuracy.append(query_accuracy)
test_loss = tf.reduce_mean(test_loss)
test_accuracy = tf.reduce_mean(test_accuracy)
test_losses.append(test_loss)
test_accuracies.append(test_accuracy)
tf.print('Epoch: ', ep,
'Train gen loss: ', gen_loss,
'Train disc loss: ', disc_loss,
'Train accuracy: ', disc_accuracy,
'Test loss: ', test_loss,
'Test accuracy: ', test_accuracy)
else:
tf.print('Epoch: ', ep,
'Train gen loss: ', gen_loss,
'Train disc loss: ', disc_loss,
'Train accuracy: ', disc_accuracy)
#####################################################################################################
checkpoint.save(file_prefix = checkpoint_prefix)
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
Evaluation on test dataset
test_loss = []
test_accuracy = []
for task_no, (support_images, support_labels, query_images, query_labels) in enumerate(test_dataset_nway_grouped):
query_loss, query_accuracy = evaluation(support_images, support_labels, query_images, query_labels)
test_loss.append(query_loss)
test_accuracy.append(query_accuracy)
test_loss = tf.reduce_mean(test_loss)
test_accuracy = tf.reduce_mean(test_accuracy)
tf.print('Test loss: ', test_loss,
'Test accuracy: ', test_accuracy)
Test loss: 1.80416536 Test accuracy: 0.628600478
As we said before, we don’t need generator to be perfect. Let’s see what generator has learned to generate
test_iterator = tfds.as_numpy(test_dataset_nway_grouped)
Run following cells multiple times to check generated images conditioned on different tasks.
test_task = next(test_iterator)
support_images, support_labels, query_images, query_labels = test_task
generated = generator([generate_noise((tf.shape(support_images)[0], noise_dim)), task_encoder(support_images)])
Real task images.
fig = plt.figure(figsize=(5,5))
for i in range(5*5):
plt.subplot(5, 5, i+1)
plt.imshow(support_images[i, :, :, -1], cmap='gray')
plt.axis('off')
plt.show()

Generated images from generator conditioned on same task.
fig = plt.figure(figsize=(5,5))
for i in range(5*5):
plt.subplot(5, 5, i+1)
plt.imshow(generated[i, :, :, -1], cmap='gray')
plt.axis('off')
plt.show()
